zynq xc7z030 board – FII-PE7030 Experiment 9 – Use Dual-port RAM to Read and Write Frame Data
Experiment 9 Use Dual-port RAM to Read and Write Frame Data
9.1 Experiment Objective
- Learn to configure and use dual-port RAM
- Learn to use synchronous clock to control the synchronization of frame structure
- Learn to use asynchronous clock to control the synchronization of frame structure
- Use ILA to observe the structure of a synchronized clock frame
- Extended the use of dual-port RAM
- Design the use of three-stage state machine
Experiment Implement
- Use ILA to observe the structure of a synchronized clock frame
- Extended the use of dual-port RAM
- Design the use of three-stage state machine
- Design a 16-bit data frame
- Data is generated by an 8-bit counter: Data={~counta,counta}
- The ID of the data frame inputted by the switch (7 bits express maximum of 128 different data frames)
- 16-bit checksum provides data verification
- 16-bit checksum accumulates, discarding the carry bit
- After the checksum is complemented, append to the frame data
- Provide configurable data length data_len by parameter
- Packet: When the data and checksum package are written to the dual-port RAM, the userID, the frame length and the valid flag are written to the specific location of the dual-port RAM. The structure of the memory is shown in Table 9.1.
Table 9.1 Memory structure
| Wr_addr | Data/ Flag | Rd_addr |
| 8’hff | {valid,ID,data_len} | 8’hff |
| … | N/A | … |
| 8’hnn+2 | N/A | 8’hnn+2 |
| 8’hnn+1 | ~checksum+1 | 8’hnn+1 |
| 8’hnn | datann | 8’hnn |
| … | …. | … |
| 8’h01 | Data1 | 8’h01 |
| 8’h00 | Data0 | 8’h00 |
- Read and write in an agreed order
valid is the handshake signal. This flag provides the possibility of read and write synchronization, so the accuracy of this signal must be ensured in the program design.
9.3 Experiment
9.3.1 Program Introduction
The first step: the establishment of the main program framework (interface design)
| module frame_ram
#(parameter data_len=250) ( input inclk_p, input inclk_n, input rst, input [6:0] sw, output reg [6:0] oID, output reg rd_done, output reg rd_err ); |
The second step: definition of state machine
| parameter [2:0] mema_idle=0,
mema_init=1, mema_pipe0=2, mema_read0=3, mema_read1=4, mema_wr_data=5, mema_wr_chsum=6, mema_wr_done=7; parameter [2:0] memb_idle=0, memb_init=1, memb_pipe0=2, memb_read0=3, memb_read1=4, memb_rd_data=5, memb_rd_chsum=6, memb_rd_done=7; |
The third step: definition of others
| Clock variable definition
wire sys_clk; wire BCD_clk; wire sys_rst; reg ext_clk; Dual-port RAM interface definition reg [7:0] addr_a; reg [15:0] data_a; reg wren_a; wire [15:0] q_a; reg [7:0] addr_b; reg wren_b; wire [15:0] q_b; Write state machine part variable definition reg [6:0] user_id; reg [7:0] wr_len; reg [15:0] wr_chsum; wire wr_done; reg [7:0] counta; wire [7:0] countb; assign countb=~counta; reg [15:0] rd_chsum; reg [7:0] rd_len; reg [15:0] rd_data; reg ext_rst; reg [2:0] sta; reg [2:0] sta_nxt,; Read state machine part variable definition reg [15:0] rd_chsum; reg [7:0] rd_len; reg [15:0] rd_data; reg [2:0] stb; reg [2:0] stb_nxt; |
The fourth step: genertae dual-port RAM, PLL
| dp_ram dp_ram_inst
( .address_a (addr_a), .address_b (addr_b), .clock (sys_clk), .data_a (data_a), .data_b (16’b0), .wren_a (wren_a), .wren_b (wren_b), .q_a (q_a), .q_b (q_b) ); pll_sys_rst pll_sys_rst_inst ( .inclk (inclk), .sys_clk (sys_clk), .BCD_clk (BCD_clk), .sys_rst (sys_rst) ); |
The RAM is 16 bits wide and 256 in depth. The PLL inputs a 50MHz clock and outputs 100MHz as the working clock of other modules, and 20MHz is used to drive the segment display.
The fifth step: data generation counter
| always @ (posedge sys_clk)
if(sys_rst) begin counta <= 0; user_id <= 0; end else begin counta <=counta + 1; user_id <= sw; end |
The sixth step: write state machine
| assign wr_done = (wr_len == (data_len – 1’b1));
//Think why using wr_len==data_len-1, instead of wr_len==data_len //First stage always @ (posedge sys_clk) begin if (sys_rst) begin sta = mema_idle; end else sta = sta_nxt; end //Second stage always @ (*) begin case (sta) mema_idle : sta_nxt = mema_init; mema_init : sta_nxt = mema_pipe0; mema_pipe0 : sta_nxt = mema_read0; mema_read0 : begin if (!q_a[15]) sta_nxt = mema_read1; else sta_nxt = sta; end mema_read1 : begin if (!q_a[15]) sta_nxt = mema_wr_data; else sta_nxt = sta; end mema_wr_data : begin if (wr_done) sta_nxt = mema_wr_chsum; else sta_nxt = sta; end mema_wr_chsum : sta_nxt = mema_wr_done; mema_wr_done : sta_nxt = mema_init; default : sta_nxt = mema_idle; endcase end |
| //Third stage
always @ (posedge sys_clk) begin case (sta) mema_idle : begin addr_a <= 8’hff; wren_a <= 1’b0; data_a <= 16’b0; wr_len <= 8’b0; wr_chsum <= 0; end mema_init, mema_pipe0, mema_read0, mema_read1 : begin addr_a <= 8’hff; wren_a <= 1’b0; data_a <= 16’b0; wr_len <= 8’b0; wr_chsum <= 0; end mema_wr_data : begin addr_a <= addr_a + 1’b1; wren_a <= 1’b1; data_a <= {countb, counta}; wr_len <= wr_len + 1’b1; wr_chsum <= wr_chsum + {countb, counta}; end mema_wr_chsum : begin addr_a <= addr_a + 1’b1; wr_len <= wr_len + 1’b1; wren_a <= 1’b1; data_a <= (~wr_chsum) + 1’b1; end mema_wr_done : begin addr_a <= 8’hff; wren_a <= 1’b1; data_a <= {1’b1, user_id, wr_len}; end default : ; endcase end |
Write order:
- Read the flag of the 8’hff address (control word). If valid=1’b0, the program proceeds to the next step, otherwise waits
- Address plus 1, 8’hff+1 is exactly zero, write data from 0 address and calculate the checksum
- Determine whether the interpretation reaches the predetermined data length. If so, proceeds to next step, otherwise the data is written, and the checksum is calculated.
- checksum complements and write to memory
- Write the control word in the address 8’hff, packet it
The sevneth step: read state machine
| //first stage
always @ (posedge sys_clk) begin if (!ext_rst) begin stb = memb_idle; end else stb = stb_nxt; end //second stage always @ (*) begin case (stb) memb_idle : stb_nxt = memb_init; memb_init : stb_nxt = memb_pipe0; memb_pipe0 : stb_nxt = memb_read0; memb_read0 : begin if (q_b[15]) stb_nxt = memb_read1; else stb_nxt = memb_init; end memb_read1 : begin if (q_b[15]) stb_nxt = memb_rd_data; else stb_nxt = memb_init; end memb_rd_data : begin if(rd_done) stb_nxt = memb_rd_chsum; else stb_nxt = stb; end memb_rd_chsum : stb_nxt = memb_rd_done;
memb_rd_done : stb_nxt = memb_init; default : stb_nxt = memb_idle; endcase end |
| // Third stage, the actual operation needs to be driven by the edge of the clock.
always @ (posedge sys_clk) begin case (stb) memb_idle : begin addr_b <= 8’hff; rd_data <= 0; rd_chsum <= 0; wren_b <= 1’b0; rd_len <= 8’b0; oID <= 7’b0; rd_err <= 1’b0; end memb_init : begin addr_b <= 8’hff; rd_data <= 0; rd_chsum <= 0; wren_b <= 1’b0; rd_len <= 8’b0; oID <= 7’b0; rd_err <= 1’b0; end memb_pipe0 : begin addr_b <= 8’b0; end memb_read0 : begin if (q_b[15]) addr_b <= addr_b + 1’b1; else addr_b <= 8’hff; rd_data <= 0; rd_chsum <= 0; wren_b <= 1’b0; rd_len <= 8’b0; oID <= 7’b0; end memb_read1 : begin if(q_b[15]) addr_b <= addr_b + 1’b1; else addr_b <= 8’hff; rd_data <= 0; rd_chsum <= 0; wren_b <= 1’b0; rd_len <= q_b[7:0]; oID <= q_b[14:8]; end memb_rd_data : begin addr_b <= addr_b + 1’b1; rd_data <= q_b; rd_chsum <= rd_chsum + rd_data; wren_b <= 1’b0; rd_len <= rd_len – 1’b1; end memb_rd_chsum : begin addr_b <= 8’hff; wren_b <= 1’b0; if (|rd_chsum) rd_err <= 1’b1; end memb_rd_done : begin addr_b <= 8’hff; wren_b <= 1’b1; end default : ; endcase end |
Read order
- idle is the state after reset
- Init: Initialization, set the address to 8’hff
- Rd_pipe0: Add a latency (since the read address and data are both latched). Address +1, forming a pipeline structure
- Read0: Set the address to 8’hff, read the control word and judge whether the valid bit is valid.
- If valid=1’b1, address +1, proceeds to the next step
- If valid=1’b0, it means the packet is not ready yet, the address is set to be 8’hff and returns to the init state.
- Read1: Read the control word again
- If valid=1’b1, address+1, ID and data length are assigned to the corresponding variables and proceeds to the next step
- If valid=1’b0, it means the packet is not ready yet, the address is set to 8’hff, and returns to the init state.
- Rd_data:
- Read data and pass to data variables
- Calculate checksum, data_len – 1
- Determine whether the data_len is 0
- 0: all data has been read, proceeds to the next step
- Not 0: continue the operation in current state
- rd_chsum: Read the value of checksum and calculate the last checksum. Correct the data and set the flag of rd_err
- rd_done: The last step clears the valid flag in memory and opens the write enable for the next packet.
9.4 Experiment Verification
The first step: add constraints and assign pins
The pin assignment is shown in Table 9.1.
Table 9.1 Dual-port RAM read an dwrite fram data experiment pin mapping table
| Signal Name | Network Name | FPGA Pin | Port Description |
| inclk_p | SYSCLK_P | AC13 | Input clock(differental)
200MHz |
| inclk_n | SYSCLK_N | AD13 | |
| rst | GPIO_SW_2 | F4 | Reset |
| sw[0] | GPIO_DIP_SW0 | A17 | 8-bit switch |
| sw[1] | GPIO_DIP_SW1 | E8 | |
| sw[2] | GPIO_DIP_SW2 | C6 | |
| sw[3] | GPIO_DIP_SW3 | B9 | |
| sw[4] | GPIO_DIP_SW4 | B6 | |
| sw[5] | GPIO_DIP_SW5 | H6 | |
| sw[6] | GPIO_DIP_SW6 | H7 | |
| oID[0] | SEF_PA | J10 | 7-bit LED
(segment display) Indicate output address |
| oID[1] | SEF_PB | J9 | |
| oID[2] | SEF_PC | A7 | |
| oID[3] | SEF_PD | B7 | |
| oID[4] | SEF_PE | A8 | |
| oID[5] | SEF_PF | A9 | |
| oID[6] | SEF_PG | A10 | |
| rd_err | GPIO_DIP_SW7 | G9 | Read error signal |
| rd_done | SEF_DP | B10 | Read end signal |
The second step: observe the read and write results of the dual-port RAM with ILA
- In order to facilitate the observation of the read and write state machine synergy results, the data length is changed to 4 here, recompile and download. Users can test themselves using long data
| module frame_ram
#(parameter data_len=4) ( input inclk_p, input inclk_n input rst, input [6:0] sw, output reg [6:0] oID, output reg rd_done, output reg rd_err ); |
- Observe the simulation result
- Observe the handshake mechanism through dual-port RAM
- Determine whether the reading is started after the packet is written
- Determine whether the write packet is blocked before reading the entire packet is completed.
- Observe the external interface signal and status
- rd_done, rd_err
Set rd_err = 1, or the rising edge is the trigger signal to observe whether the error signal is captured.
- Observe whether wren_a, wren_b signal and the state machine jump are strictly matched to meet the design requirements.
- ILA result, see Figure 9.1.
The third step: run the implementation, generate bitstream files, and verify the board
After successfully downloading the generated programmable bitstream file to the Zynq_7030 development board, the experimental phenomenon is shown in Figure 9.1.
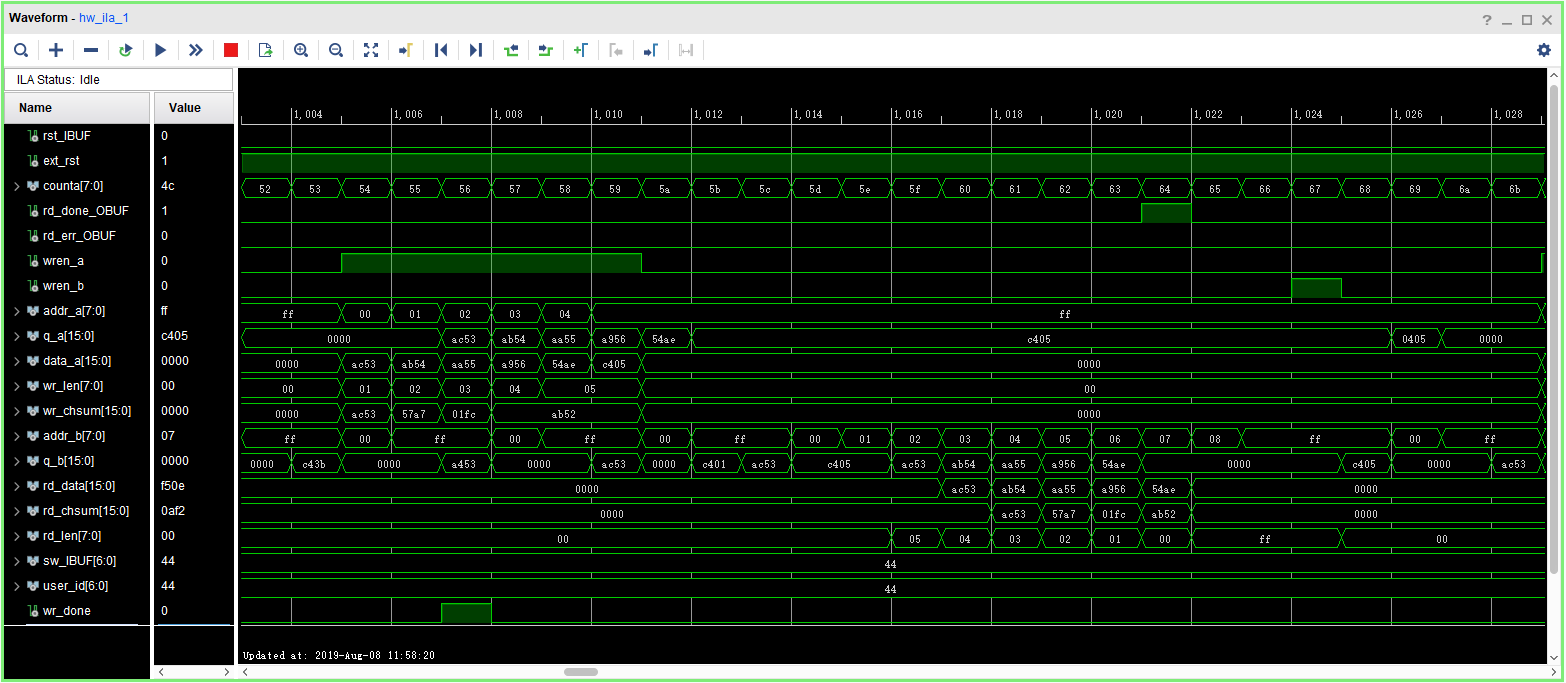
Figure 9.1 Experimental phenomenon
9.5 Experiment Summary and Reflection
- Review the design requirements. How to analyze an actual demand, to gradually establish a model of digital control and state machine and finally design.
- Modify the third stage of the state machine into the if…else model and implement.
- Focus on thinking If the read and write clocks are different. After it becomes an asynchronous mechanism, how to control the handshake.
- According to the above example, consider how dual-port RAM can be used in data acquisition, asynchronous communication, embedded CPU interface, and DSP chip interface.
- How to build ITCM with dual-port RAM and DTCM preparing for future CPU design.